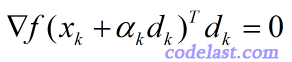友情提示:如果觉得页面中的公式显示太小,可以放大页面查看(不会失真)。
Logistic Regression(或Logit Regression),即逻辑回归,简记为LR,是机器学习领域的一种极为常用的算法/方法/模型。
你能从网上搜到十万篇讲述Logistic Regression的文章,也不多我这一篇,但是,就像我写过的最优化系列文章一样,我仍然试图用“人话”来再解释一遍——可能不专业,但是容易看得懂。那些一上来就是几页数学公式什么的最讨厌了,不是吗?
所以这篇文章是写给完全没听说过Logistic Regression的人看的,我相信看完这篇文章,你差不多可以从无到有,把逻辑回归应用到实践中去。