查看本系列文章合集,请看这里。
为 training 数据做标注,这可能是一个艰巨的任务,也可能是一个有捷径的任务。
有时候,我们可以依据一些已知的规则来标注文本,比如不同的数据是从不同的来源获取到的,从来源可以知道它们所属的类别,这是一个捷径。不过我这里不具备这样的条件。
我的数据来源是网上的各种新闻,不是某些专业领域的数据,这种比较常见的文本分类任务,可以利用国内的几大云服务商提供的免费接口来完成。阿里云、腾讯云都有这样的接口。
以腾讯云为例,其“人工智能→自然语言处理”产品提供了文本分类功能:
文本分类接口能够对用户输入的文本进行自动分类,将其映射到具体的类目上,用户只需要提供待分类的文本,而无需关注具体实现。该功能基于千亿级大规模互联网语料和LSTM、BERT等深度神经网络模型进行训练,并持续迭代更新,以保证效果不断提升。目前已提供:● 通用领域分类体系,包括15个分类类目,分别是汽车、科技、健康、体育、旅行、教育、职业、文化、军事、房产、娱乐、女性、奥运、财经以及其他,适用于通用的场景。● 新闻领域分类体系,包括37个一级分类类目,285个二级分类(详细请见 类目体系映射表),已应用于腾讯新闻的文章分类。更多垂直领域的分类体系即将推出,敬请期待。默认接口请求频率限制:20次/秒。
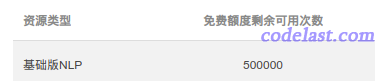
如果你对这个接口的分类结果准确性有疑虑的话,可以亲自拿一些新闻的文本试一试,就会发现它的效果真的不错,完全可以用来当作人工标注的结果了,毕竟是大厂出品嘛。
同理,阿里云也有类似的接口。作为电商界的龙头,阿里云的文本分类接口不仅适用于新闻资讯领域类目体系,还能用于电商领域类目体系。所以,如果你的文本是电商领域的,可以试试阿里云。
文章来源:https://www.codelast.com/
下面,就来看看怎么薅腾讯云的羊毛。注册腾讯云账号、开通自然语言处理接口的权限,这些就不用说了,自己在网页上点几下就可以完成。
✓ 测试接口
腾讯云NLP接口提供了一个在线测试的网页,从这个链接可以进去(“点击调试”):

进入调试页面:
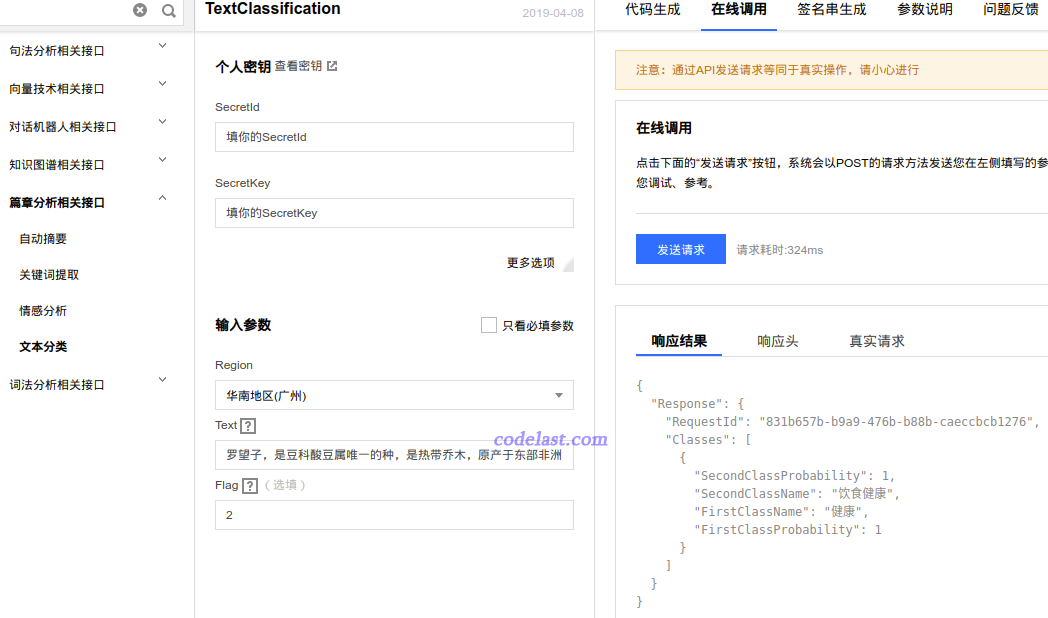
对这个接口:
Region只能选“华南地区(广州)”。
Text是待分类的文本,注意不需要分词。只需要把我们前面清洗过(去掉了HTML tag等内容)的句子拿来用即可。
Flag为 1 表示通用领域,为 2 表示新闻领域。
文章来源:https://www.codelast.com/
接口返回的数据是JSON格式,FirstClassName 是一级分类的名称,SecondClassName 是二级分类的名称。
调试页面还提供了“代码生成”功能,Java、Python、PHP、Go等都有,支持非常全面。选一个你熟悉的语言,就可以在代码里实现了。
由于免费的接口的QPS上限为20次/秒,所以并行什么的就不要想了,单线程就能跑满。
通过腾讯云的接口,我们能在半天内为几十万条文本打上标签,再整理成 fastText 规定的格式,就可以训练模型了。
如果觉得50万条都不够多,可以注册多个腾讯云账号来薅羊毛,或者用几天的时间累积够标注数据。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):
