BAIR(Berkeley Artificial Intelligence Research,伯克利人工智能研究所),开源了一个强化学习(RL)框架 rlpyt,并于2019.09.24在其主页上对它进行了很长篇幅的介绍(论文在这里)。
市面上开源强化学习框架已经很多了,这个框架是否值得你上车?我认为,未来怎样不好说,但至少现在(2019.10)看来是值得入手的,因为它确实有其他框架不具备/不完善的功能——最主要的就是对并行(parallelism)的良好支持。
在强化学习领域,agent与environment互动来收集training data的过程是最耗时的,如果能并行地用多个agent与多个environment互动来收集数据,那么速度可以极大提升。类似于Google Dopamine这样的RL框架,根本没有把 parallelism 作为设计理念的一部分,所以如果你入了Dopamine的坑,等你对模型训练速度有要求的时候再想着换框架,成本就高多了。
▶ rlpyt 这个框架的主要特色是什么?
这里没打算把BAIR对 rlypt 的介绍它全部重新写一遍,只提一些我认为重要的特点:
- 适用于小型、中型的强化学习实验。什么叫中型?举个“大型”的例子:像OpenAI的Dota那种使用上百个GPU的强化学习实验叫“大型”。对一般的RL应用来说,这个适用范围绰绰有余了。
- 可以用串行方式运行,也可以完全并行的方式运行采样器(采样就是指agent与environment交互获取training data的过程),并且支持用CPU或GPU训练,也支持用单GPU或多GPU来优化(优化指的是强化学习算法里更新网络参数的操作)。
- 实现了各种主流RL算法,例如A2C,PPO,DQN,Double DQN,Dueling DQN,Rainbow,DDPG等(这里不一一列出),可以说是比较全面了。
文章来源:https://www.codelast.com/
▶ 你也需要知道的一些事实
- rlpyt 是基于PyTorch开发的,它利用了PyTorch的很多特性。如果你想用TensorFlow,那只能出门右转去下一家了。
- rlpyt 中包含的并行性仅限于单节点情况——尽管它的组件可以作为分布式框架的构建块。这里的意思大概是说,只能在一台物理机上使用rlpyt,并行是发生在这台机器内的,不能在多台物理机上并行。
文章来源:https://www.codelast.com/
▶ 下面来说一下 rlpyt 的并行功能
下面是官方的图:
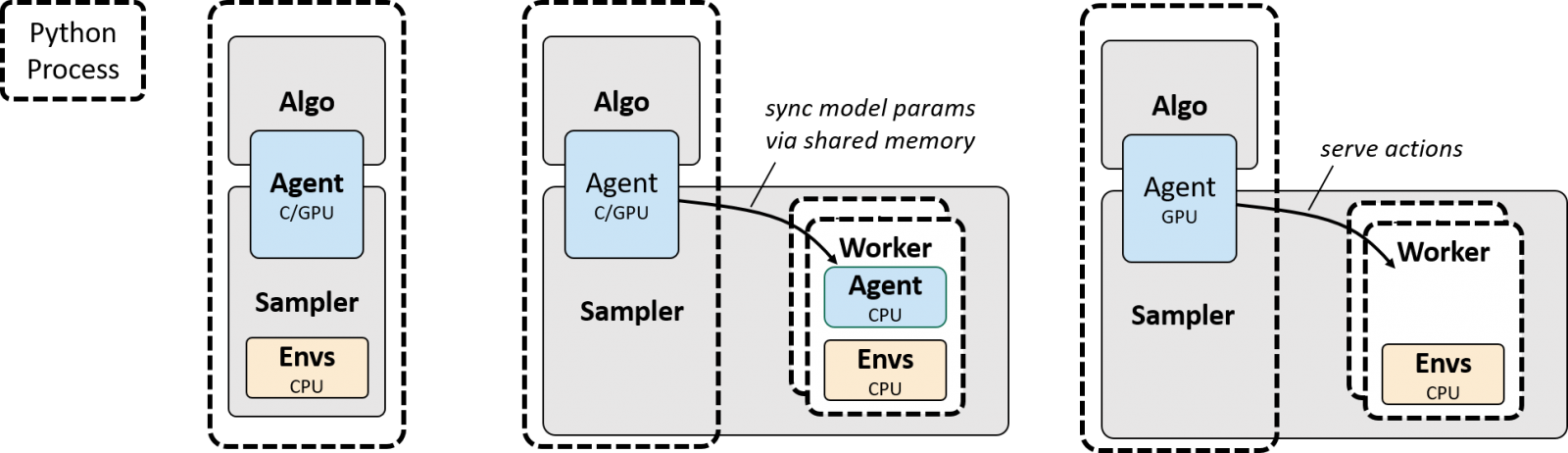
虚线表示一个Python进程。
左图表示以Serial(串行)方式来训练模型,这种方式就跟其他大多数RL框架提供的功能一样,平淡无奇。
中图表示以Parallel-CPU(CPU并行)的方式来训练模型,这有就点意思了:你可以在多个CPU上运行多个worker,每个worker自带agent的一个副本,在worker内选择action,与environment交互。尽管worker是运行在CPU上的,但你仍然可以把优化(optimization)设置成跑在GPU上,当你这样做的时候,模型参数会被拷贝到共享内存(shared memory)上,供CPU使用来选择action——因为action selection是在CPU上做的,因此CPU需要知道网络的参数,如果这些参数在GPU上,CPU要能获取到才能使用。
右图表示以Parallel-GPU(GPU并行)的方式来训练模型,这就更有意思了:仍然在多个CPU上运行多个worker来与environment交互,但在交互的过程中,并不是在每个worker内部做的action selection,把所有worker里的observation(可以理解为state,或feature)汇总到一个主进程里去做action selection。假设你把优化(optimization)设置成跑在GPU上,那么这些action selection也会使用GPU来完成。这样做的好处是什么?大家知道对Deep RL来说,action selection其实就是神经网络正向传播的过程,因此如果能利用GPU的话,也是能快不少的。
还有一种并行模型,rlpyt 称之为 Alternating-GPU(交替GPU) 模式,这种模式和右图的GPU并行模式差不多,但与之不同的是,它有两组worker,其中一组用于在environment中步进(同样不做action selection),另一组就等着做action selection的工作。我从直观介绍上来看,认为它就是加强了Parallel-GPU模式下的action selection那一块的能力,使得负责action selection的主进程在某些情况下不至于“忙不过来”,不知道这样理解对不对。
这么丰富的并行(parallelism)方式支持,可以说是不知道比市面上的其他RL框架要强了多少倍了,管它们是什么大公司出品的,rlpyt 照样能把它们的脸踩在地上使劲摩擦。
文章来源:https://www.codelast.com/
▶ 下面再来说一说 rlpyt 的优化(optimization)功能
依然引用官方的原图:
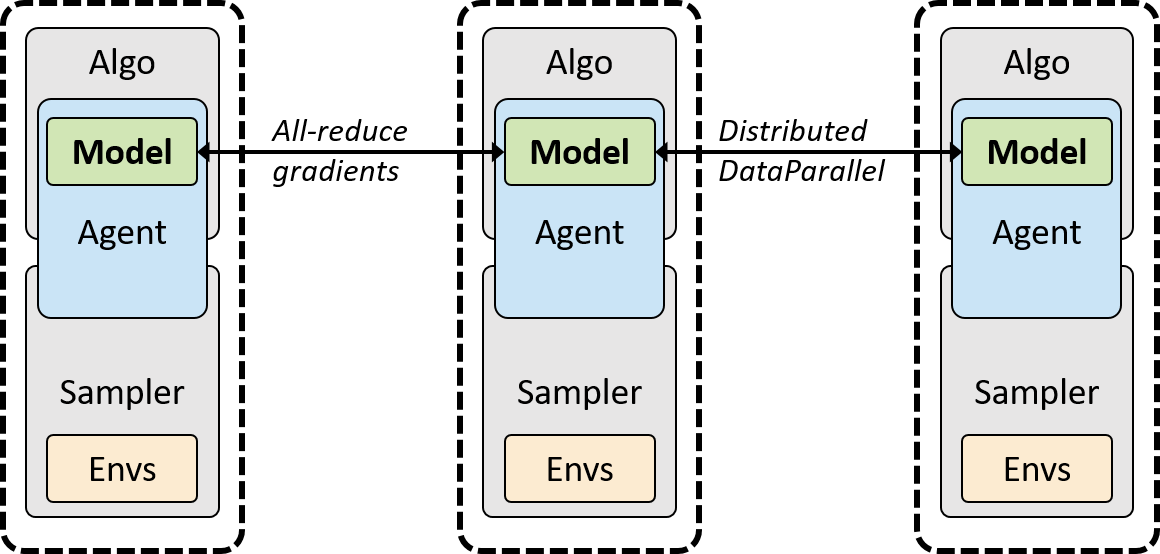
上面是 rlpyt 支持的一种优化模式,称之为同步多进程优化模式(按我的理解这仅限于GPU并行模式),一个虚线框代表一个Python进程,它在每一个Python进程里都运行一个完整的[采样器-算法]栈的副本(图里的[Sampler-Algo]),并在PyTorch的DistribuedDataParallel类的反向传播期间隐式强制执行同步。前面说了 rlpyt 为什么要基于 PyTorch 开发,是因为它依赖于 PyTorch 的很多特性,这里就是一个。
这里的All-Reduce是什么呢?
在同步数据并行分布式深度学习中,主要的计算步骤是:(1) 在每个GPU上使用一个minibatch来计算loss function的梯度(2) 通过GPU间的通信计算梯度的均值(3) 更新模型AllReduce就是用来计算上面第2步中的多GPU之间梯度的均值的方法。
文章来源:https://www.codelast.com/
除了上面的同步模式,rlpyt 还支持一种异步采样/优化模式,如下图所示:
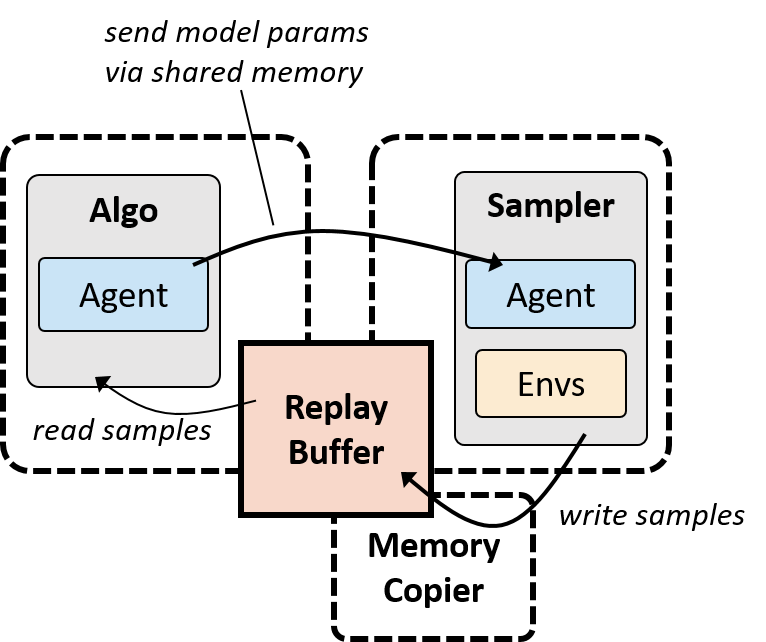
文章来源:https://www.codelast.com/
▶ 高亮案例
为了说明 rlpyt 有多好,BAIR对Atari游戏进行了R2D2(Recurrent Replay Distributed DQN)的重现。
R2D2是发表在ICLR 2019上的一篇论文,当时取得了Atari游戏上的“当前最优”效果,并且它之前只能在分布式计算下实现——所以 rlpyt 要拿它来下手,表示:我也可以做到啊!
R2D2有多牛?据它的论文称,它是第一个使用单一网络架构和固定的超参数集就实现了如下目标的架构:大幅超越Atari-57游戏集上的当前最先进水平,以及不输于DMLab-30游戏集的当前最先进水平。
R2D2的论文使用了256个CPU,一个GPU,每秒能走66000步;而 rlpyt 在一台工作站上,仅用了 24个不怎么先进的CPU,以及3个Titan-Xp GPU,就达到了每秒走16000步,这已经可以达到在单机上进行实验的条件了。
这有力地表明了:rlpyt 对并行(parallelism)的支持就是很厉害啊。
文章来源:https://www.codelast.com/
▶ 基于TensorFlow的RL框架,就没有和 rlpyt 水平差不多的吗?
所以有人会说,现在基于TensorFlow的RL框架,在并行(parallelism)这个功能点上,一个能打的都没有吗?受限于我的知识,我不敢说当前(2019.10)的TF-based RL框架都很挫,但就我调研过的那些来说,好像确实是一个真●能打的都没有。
- 光看Google自己出品的那些RL框架,什么Dopamine,TF-Agents,目前都没有对并行的支持,而且都还不是Google的正式产品;还有一个2015年就发了论文的Gorilla,它应该不是一个框架,而是一个架构,但它号称是支持大规模并发DRL的架构,不过这玩意并不开源啊。感觉就是Google内部,现在还没有扶持一个“正牌”的产品上位,各个RL团队们在为了KPI各自为战,而Google现在还没有想在开源世界里把哪个团队的RL框架扶植到TensorFlow那种地位上,等哪天Google真的下定决心想把这事给做好了,我们恐怕才有机会在Google那里看到一个像样的RL框架。
- 如果把DeepMind的开源产品也算做Google的话,那么还有类似于TRFL这样的RL lib,但是截至目前它都已经半年多没更新了好吗,看样子DeepMind自己都要放弃它了。
- 还有其他一些RL框架,是在Ray这个分布式框架的基础上搭建的,比如RLlib,可能会把小的实验复杂化。
- 一个最有力的竞争者恐怕就是Tensorforce了,当前该框架仍然处于活跃的开发中,并且它是支持并行的!但并行功能没有 rlpyty 支持的那么丰富。从一些文章的介绍中可以看出来,如果你是TensorFlow的死忠,这个框架可能是你当前的最优选择了。不过也需要提醒一下,Tensorforce是剑桥大学的几个博士生在开发维护,Tensorforce原来的主页已经挂了,现在只剩GitHub源码页,不知道会不会有后续开发保障。
综上所述,如果你在找一款强化学习开发框架,并且你对使用 PyTorch 或 TensorFlow 没有特别的偏好,同时你还对强化学习实验的并行(parallelism)过程十分在意,那么 rlpyt 可能是你的当前最好选择;如果你非得上TensorFlow的船,那么 TensorForce 或者基于Ray的框架就可能是你的当前最好选择。
2020-09-10 更新:
在 rlpyt 发布约一年后,来自清华的“天授”强化学习框架发布了,其主要作者是一个本科生,没错,来自清华本科生的暴击,人和人的差距就是这么大。
天授也是基于PyTorch的RL框架,通过天授发布的评测结果,可以发现其优秀程度比起 rlpyt 有过之而无不及。因此,如果你是一个正在看这篇文章,并且正在选择RL框架的人,那么,我强烈建议你可以从“天授”入手。
文章来源:https://www.codelast.com/
➤➤ 版权声明 ➤➤
转载需注明出处:codelast.com
感谢关注我的微信公众号(微信扫一扫):
